植被分类
总流程图
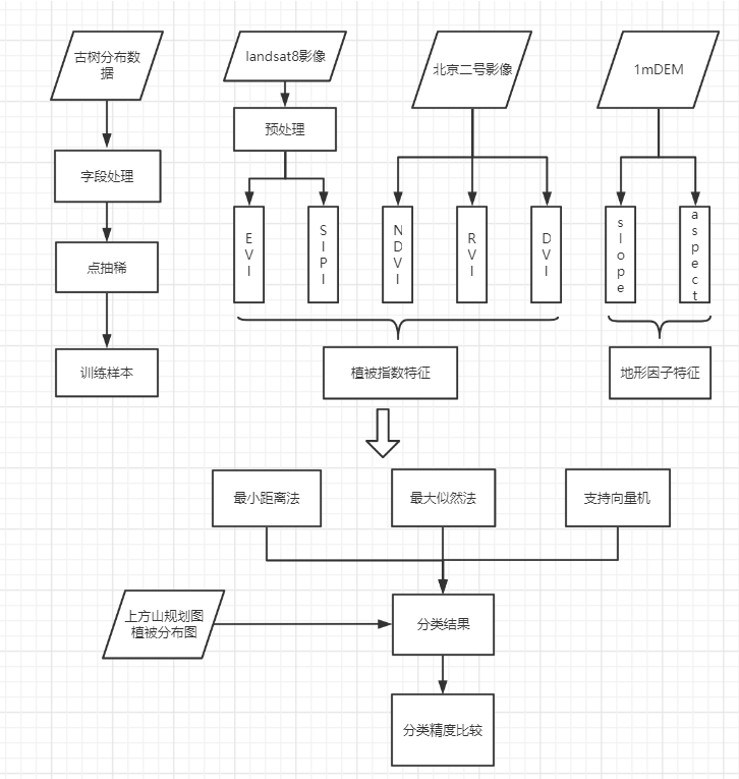
本组数据采用Landsat8影像,北京二号影像,1mDEM影像数据以及老师提供的古树分布数据进行研究。首先要进行的便是对遥感影像数据的预处理。
第一步先对数量过多的树种进行点抽稀处理,平衡各类树种样本数量。将表格中的无用字段删除,并翻译为英文,设立中英文对照表格,使用投影变换更改坐标系等,以达到样本均衡、信息精简、坐标统一的效果。
其次是进行辐射定标,计算平均高程值和大气校正等一系列操作。虽然数据本身已经进行几何校正和地形校正,但是仍然需要进行辐射定标,对遥感影像进行预处理可以提高后续分类的精度,降低误差。
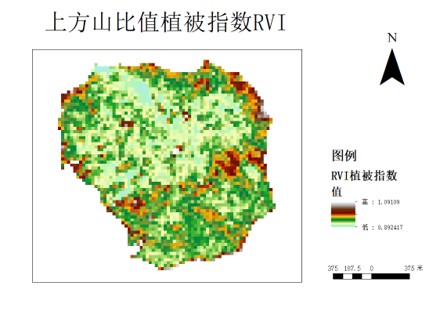
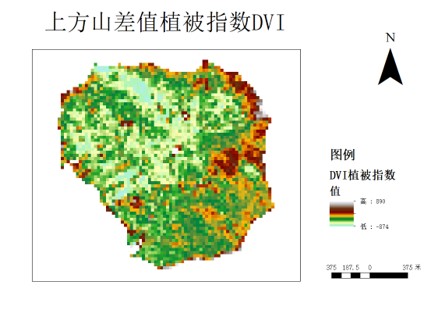
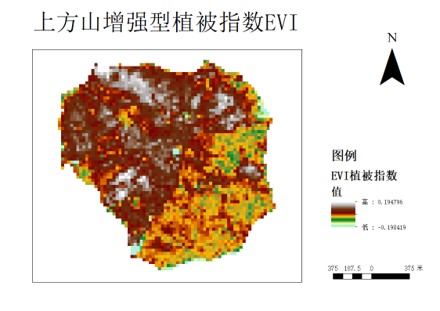
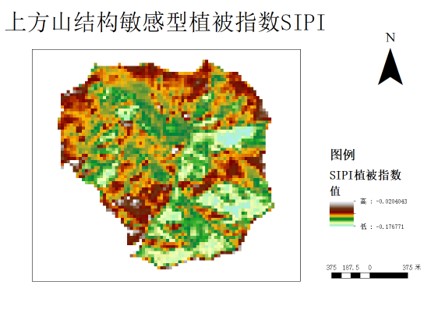
植被指数有归一化植被指数(NDVI)、比值植被指数(RVI)、差值植被指数(DVI)、调整土壤亮度植被指数(SAVI)、土壤调整植被指数(MSAVI)、增强植被指数(EVI)等,可通过植被在近红外、红光、绿光和蓝光波段的遥感反射率计算所得,其中NDVI是衡量健康植被的标准化方法。当具有较高的NDVI值,趋于1时,植被显得更健康茂密。当NDVI较低时,植被较少或没有植被,趋于0时多呈现为岩石裸地,趋于-1时多呈现雪、水等。
因此,我们对遥感数据中光谱信息通过一定数学运算得到植被指数,植被指数将用于提高树种识别精度。与此同时,我们计算了2015-2020年间该地域的ndvi回归方程来研究这六年间的上方山地区ndvi值的动态变化。选题同时也采用归一化植被指数(NDVI)、差值植被指数(DVI)、增强型植被指数(EVI)等,为下一步的分类奠定了基础。
在这一部分,本组成员使用了ENVI和ArcGis软件进行训练样本以及监督分类。其中采取了最小距离分类、最大似然分类,支持向量机的分类方法进行这一过程。
最小距离分类,是指求出未知类别向量到要识别各类别代表向量中心点的距离,将未知类别向量归属于距离最小一类的一种图像分类方法。最小距离分类法通过求出未知类别向量X到事先已知的各类别(如A,B,C等等)中心向量的距离D,然后将待分类的向量X归结为这些距离中最小的那一类的分类方法。
支持向量机,常简称为SVM,是在分类与回归分析中分析数据的监督式学习模型与相关的学习算法。. 给定一组训练实例,每个训练实例被标记为属于两个类别中的一个或另一个,SVM训练算法创建一个将新的实例分配给两个类别之一的模型,使其成为非概率二元线性分类器。
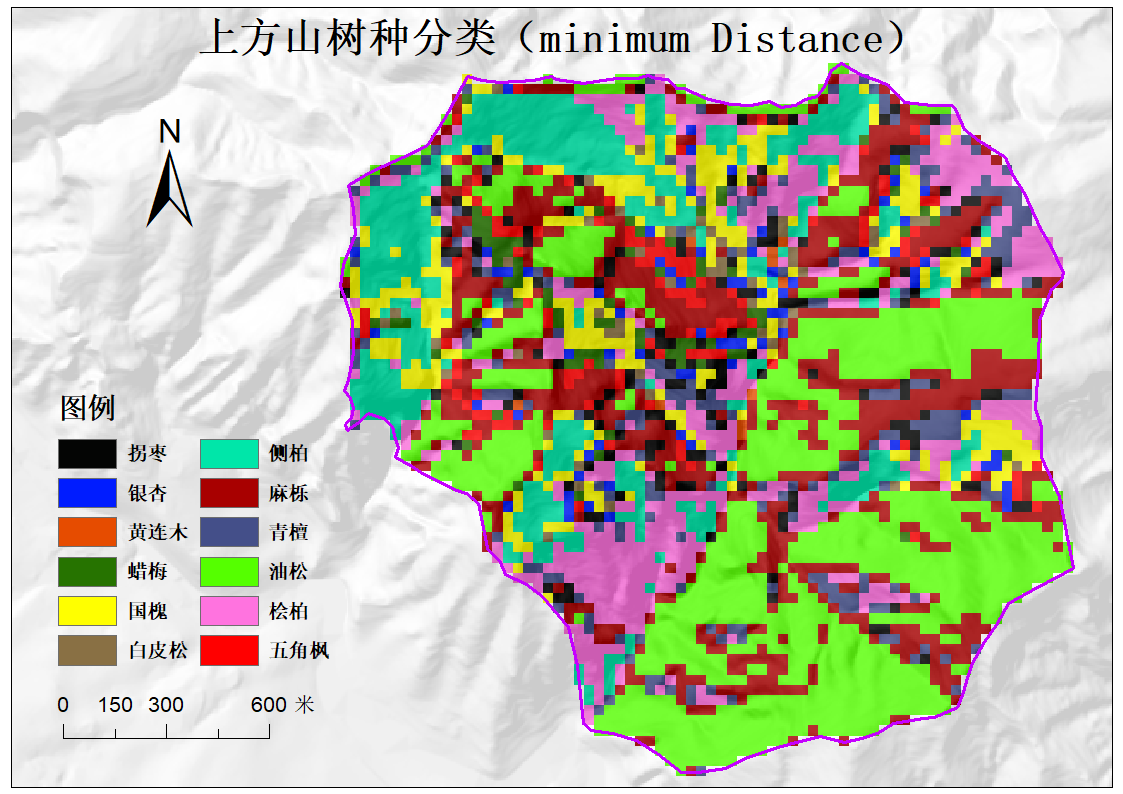
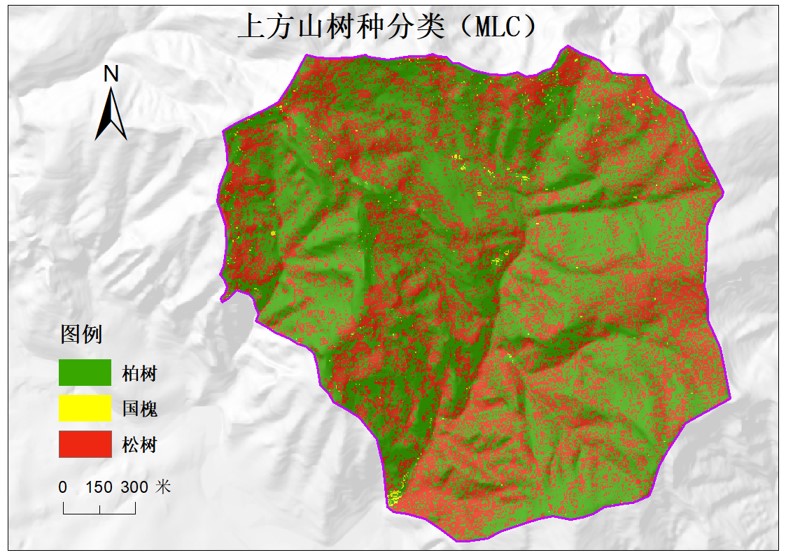
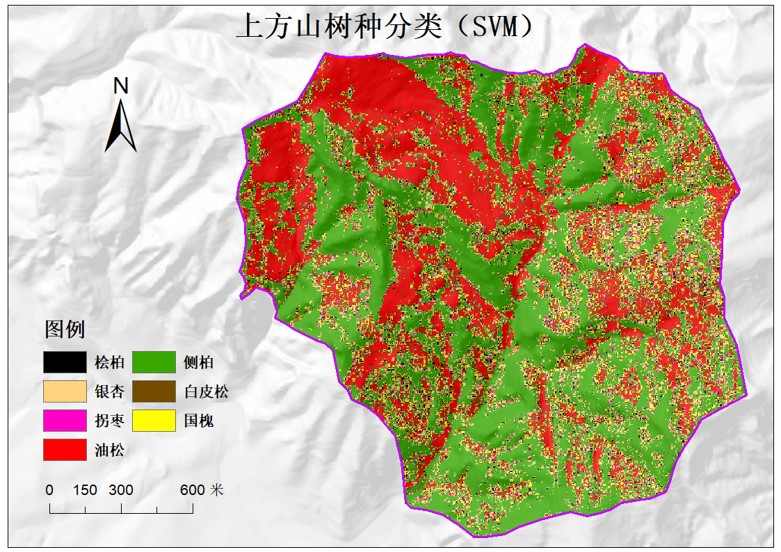
为了更好呈现其结果。我们用将地图分为多个板块进行合理分析。将结果所框出的部分与上方山管理处得到的图相同划线部分进行对比,可以看出该部分两幅图有着较高的相似性。而通过分析两幅图可以看出相似度最高的部分大多为油松和侧柏,表明该方法分析精度较为准确,并符合该地区多松柏的具体体现。
在excel表格中进行进一步操作,对每种要素的分类结果进行评价,可以看出,最小距离法和支持向量机两种方法得到的结果精度相近,但对侧柏的数量存在一定的高估最大似然法得到结果则较差。
总之不同的方法会产生不同的分类效果,对数据进行预处理之后,数据的样本量下降,难对数据进行进一步的验证集划分,因此精度评价依靠人工的定性分析。后使用上方山规划图中的植被分布图,将数据矢量化后进行面积制表操作,从而进行定量评价。
收获与感谢




